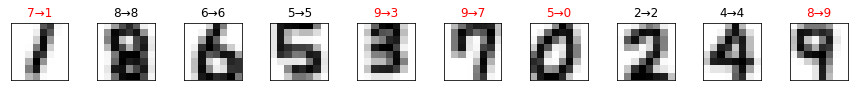夏休みの課題としてTwitterで好きな画像を収集して自動でリツイートするbotを作ろうと思い立ちました。
機械学習やTwitterのAPIに習熟するいい機会になりました。
一応の完成形にたどり着いたのでそのやり方を共有します。
1.画像を取得する対象ツイートの開始時刻と終了時刻を設定する
例えば毎日午前6時から過去24時間分の画像を収集するなら次のようにします。
from datetime import date, time, datetime, timezone, timedelta
#開始時刻と終了時刻の設定
today = date.today()
time = time(6)
end_time = datetime.combine(today, time, tzinfo=timezone(timedelta(hours=9)))
start_time = end_time - timedelta(hours=24)
#開始時刻と終了時刻の確認
print('start_time:', start_time.isoformat())
print('end_time:', end_time.isoformat())午前6時を10分ほど過ぎてから実行しないとエラーになります。
start_time: 2021-08-30T06:00:00+09:00
end_time: 2021-08-31T06:00:00+09:00このような表示になれば成功です。日付の部分は実行した日によって変わります。
2.Twitter API v2で画像を一括取得する
開始時刻から終了時刻までのツイートの中で検索ワードにマッチして画像が含まれるオリジナルツイート(リツイートではないツイート)を網羅的に取得します。
import requests
import os
import json
#定数の設定
bearer_token = "YOUR_BEARER_TOKEN"
search_url = "https://api.twitter.com/2/tweets/search/recent"
query_params = {
'query': 'テスト has:images -is:retweet',
'expansions': 'attachments.media_keys',
'media.fields': 'url',
'max_results': 100,
'start_time': start_time.isoformat(),
'end_time': end_time.isoformat(),
}
#画像URLをキー、そのツイートIDを値として格納するディクショナリを作成
results = {}
#認証用の関数
def bearer_oauth(r):
r.headers["Authorization"] = f"Bearer {bearer_token}"
r.headers["User-Agent"] = "v2RecentSearchPython"
return r
#検索エンドポイントに接続して必要なデータを取得する関数
def connect_to_endpoint(url, params):
has_next = True
while has_next:
#APIを叩いて結果を取得
response = requests.get(url, auth=bearer_oauth, params=params)
#ステータスコードが200以外ならエラー処理
print(response.status_code)
if response.status_code != 200:
raise Exception(response.status_code, response.text)
#responseからJSONを取得
json_response = response.json()
#ツイートをループしてmedia_keyをキー、ツイートIDを値とするディクショナリを作成
media_tweet_dict = {}
for tweet in json_response['data']:
if 'attachments' in tweet.keys():
for media_key in tweet['attachments']['media_keys']:
media_tweet_dict[media_key] = tweet['id']
#メディアのループ
for image in json_response['includes']['media']:
try:
results[image['url']] = media_tweet_dict[image['media_key']]
except:
pass
#次のページがあるかどうかを確かめ、あればquery_paramsにnext_tokenを追加
has_next = 'next_token' in json_response['meta'].keys()
if has_next:
query_params['next_token'] = json_response['meta']['next_token']
#実行
connect_to_endpoint(search_url, query_params)
#結果の確認
print(results)
YOUR_BEARER_TOKENという部分を自分のBearer Tokenに書き換えて、「テスト」という部分を検索したいワードに書き換えます。
うまく動けば、200という成功を表わすステータスコードと、画像URLをキー、そのツイートIDを値とするディクショナリの内容が表示されます。
Twitter API v2で画像を一括取得する – 浅野直樹の学習日記と大枠は同じです。
画像URLとツイートIDを直接紐付けることはできないので、media_keyを中間に介在させなければならないのがやや面倒です。
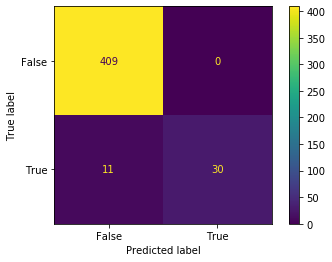
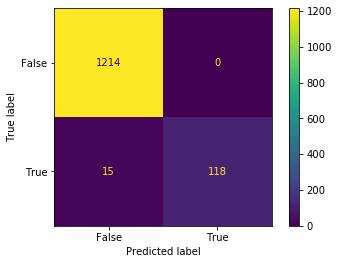
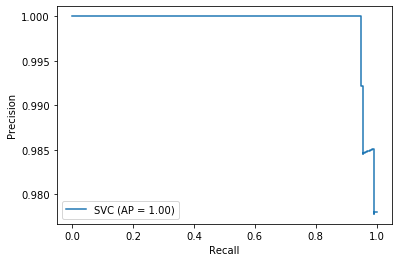
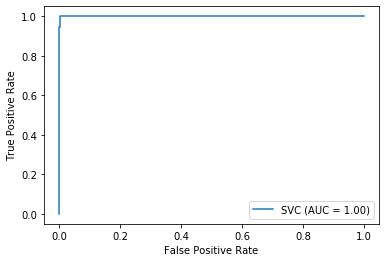
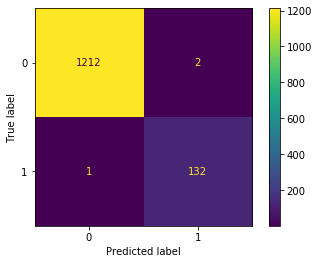
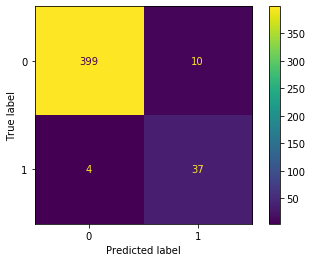
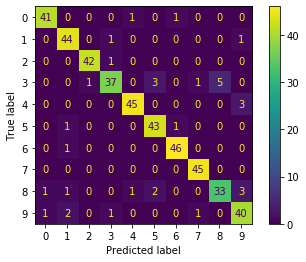
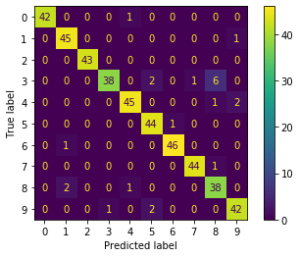
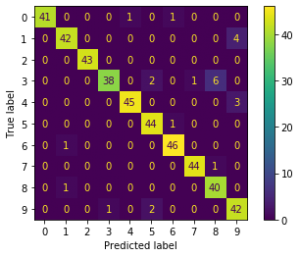
3.収集した画像にターゲットが写っているかを機械学習で判定
これも結論を載せます。
import pickle
from skimage import io, color
from skimage.transform import resize
import numpy as np
import matplotlib.pyplot as plt
#画像データとツイートIDを保存するリストをそれぞれ作成
data = []
tweet_ids = []
#事前に保存したパイプラインとしきい値をロードする
filename = 'finalized_pipe_and_threshold.sav'
loaded = pickle.load(open(filename, 'rb'))
#画像の読み込み
for k, v in results.items():
image = io.imread(k)
if image.ndim == 2:
continue
if image.shape[2] == 4:
image = color.rgba2rgb(image)
resized_image = resize(image, (64, 64))
data.append(resized_image)
tweet_ids.append(v)
#画像データを変形して機械学習の適用
X = np.array(data).reshape(len(data), -1)
y = loaded['pipe'].decision_function(X) >= loaded['threshold']
#Trueと判定されたデータとツイートIDだけを取得
true_data = [data[i] for i in range(len(data)) if y[i] == True]
ids_to_retweet = [tweet_ids[i] for i in range(len(data)) if y[i] == True]
#描画領域の確保
fig, axes = plt.subplots(10, 10, figsize=(15, 15), subplot_kw={'xticks':[], 'yticks':[]})
#Trueと判定された画像の表示
for i, ax in enumerate(axes.flat):
ax.imshow(true_data[i])
if i+1 >= len(true_data): break機械学習は事前に済ませてpickleで保存しているという前提です。
詳細はscikit-learnで機械学習をして好きな画像を自動で分類する – 浅野直樹の学習日記をご参照ください。
ここではTrueと判定された画像を表示させて目で見て確認していますが、実際に運用する際はその必要はありません。
#Falseと判定されたデータだけを取得
false_data = [data[i] for i in range(len(data)) if y[i] == False]
#描画領域の確保
fig, axes = plt.subplots(10, 10, figsize=(15, 15), subplot_kw={'xticks':[], 'yticks':[]})
#Falseと判定された画像の表示
for i, ax in enumerate(axes.flat):
ax.imshow(false_data[i])
if i+1 >= len(false_data): breakこうすればFalseと判定された画像だけを表示することもできます。
4.見つけた画像の自動リツイート
いよいよ最後のプロセスです。
from requests_oauthlib import OAuth1Session
import os
import json
#定数の設定
consumer_key = "YOUR_CONSUMER_KEY"
consumer_secret = "YOUR_CONSUMER_SECRET"
access_token = "YOUR_ACCESS_TOKEN"
access_token_secret = "YOUR_ACCESS_TOKEN_SECRET"
user_id = "YOUR_USER_ID"
#リクエストの作成
oauth = OAuth1Session(
consumer_key,
client_secret=consumer_secret,
resource_owner_key=access_token,
resource_owner_secret=access_token_secret,
)
#リツイートの実行
for tweet_id in ids_to_retweet:
payload = {"tweet_id": tweet_id}
response = oauth.post("https://api.twitter.com/2/users/{}/retweets".format(user_id), json=payload)
if response.status_code != 200:
raise Exception("Request returned an error: {} {}".format(response.status_code, response.text))
print("Response code: {}".format(response.status_code))Twitter-API-v2-sample-code/retweet_a_tweet.py at main · twitterdev/Twitter-API-v2-sample-codeを大幅に簡略化しました。
定数の部分は自分の値に設定してください。
これでリツイートした回数分だけ「Response code: 200」と表示されるはずです。
5.さいごに
ここまで来る道のりは長かったです。何度も挫折しそうになりました。
この記事では解説のためにコードを分割しましたが、本番では一つのコードにまとめて、cronで定期的に自動実行します。
一歩ずつ進めば好きな画像を自動で収集してリツイートするbotを作ることができます。